
세상에 막 태어났을 때에는 고양이와 개를 구별하지 못했을 것이다. 하지만 지금의 우리는 고양이와 개를 구별할 수 있다. 사진, 영상, 목격 등을 통해 고양이와 개의 각 특징을 발견하고 이들을 구별할 수 있도록 학습했기 때문이다. 우리의 학습 과정과 유사한 알고리즘을 통해 기계를 학습시키는 것이 바로 기계학습이다. 이번 글을 통해 기계학습의 정의와 기본 원리 그리고 기계학습의 종류에 대해 정리해 보고자 한다.
1. 기계학습(머신러닝, Machine Learning, ML)의 정의
경험(E)을 통해 컴퓨터가 주어진 지식에서 패턴을 익혀 새로운 과제(T)가 주어져도 이를 잘(P) 수행할 수 있도록 기계를 학습시키는 기술을 개발하는 분야.
▷the study of computer algorithms that improve automatically through experience.(위키백과)
컴퓨터가 경험을 통해 자동으로 (성능을) 개선할 수 있도록 하는 알고리즘과 기술을 개발하는 분야.
▷the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead.(what is machine learning?)
컴퓨터 시스템이 명시적 지시없이*패턴과 추론에 따라** 특정 과제를 수행하는 통계적 모델과 알고리즘을 연구하는 분야.
*명시적 지시 없이: 개별적인 그림(데이터)마다 얘는 고양이, 얘는 개라고 정해주는 것이 아니라,
**패턴과 추론에 따라: 패턴(특징)을 학습하여 새로운 데이터가 주어져도 이에 맞게 적용해 추론하여 답을 낼 수 있는.
▷the system reliably improves its performance measure P at task T, following experience E.
경험을 통해 과제 수행 성능을 개선하는 시스템.(Tom Mitchell, The Discipline of Machine Learning, 2016)
예) 사진, 영상, 목격 등(E, experience)을 통해
고양이와 개의 각 특징을 발견하고 이들을 구별(T, task)할 수 있도록 컴퓨터를 학습시키는 기술.
+구별하는 과제를 얼마나 잘 수행하는지: 성능척도(P, performance measure)
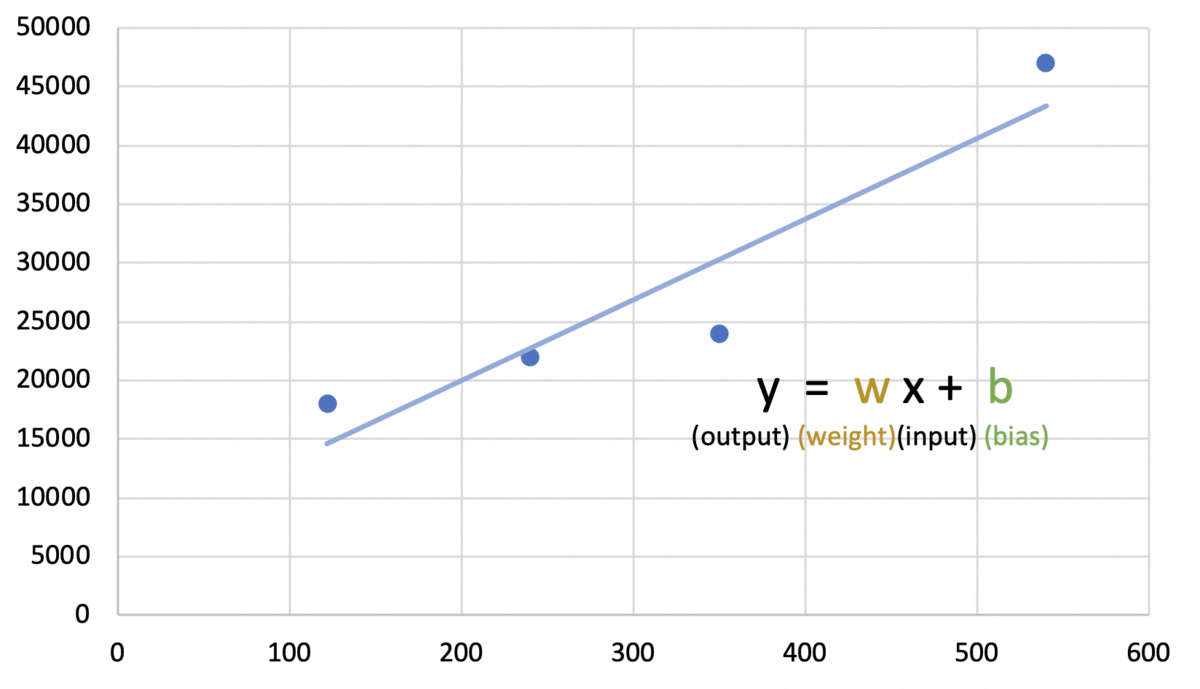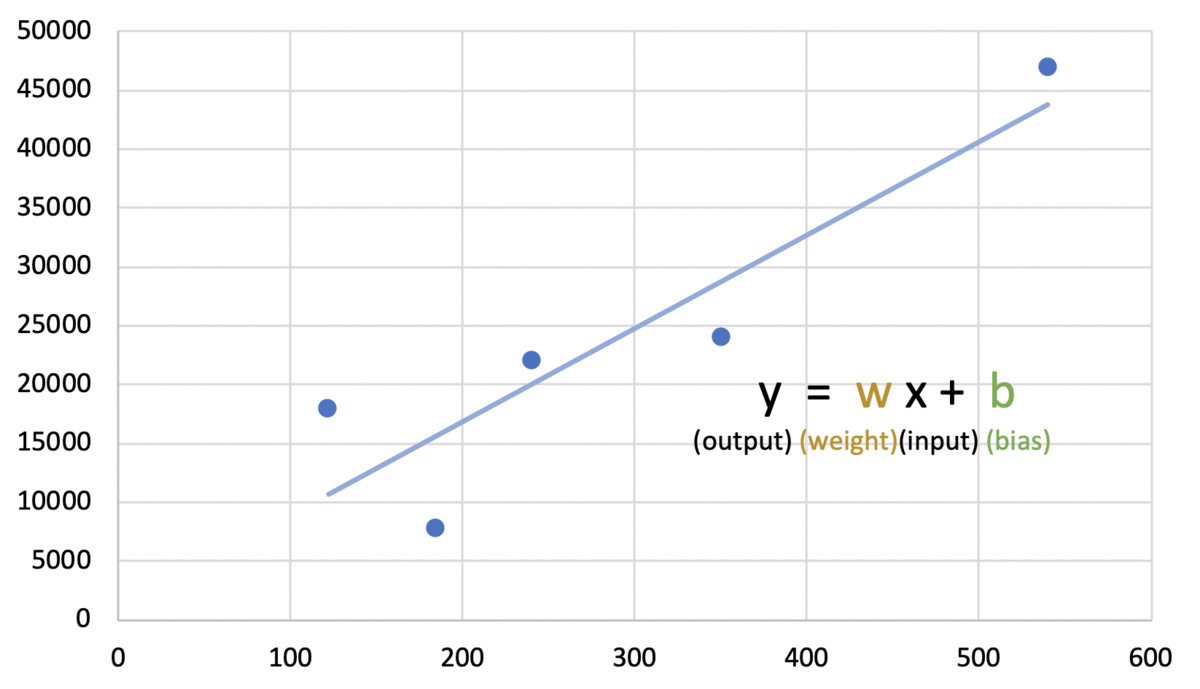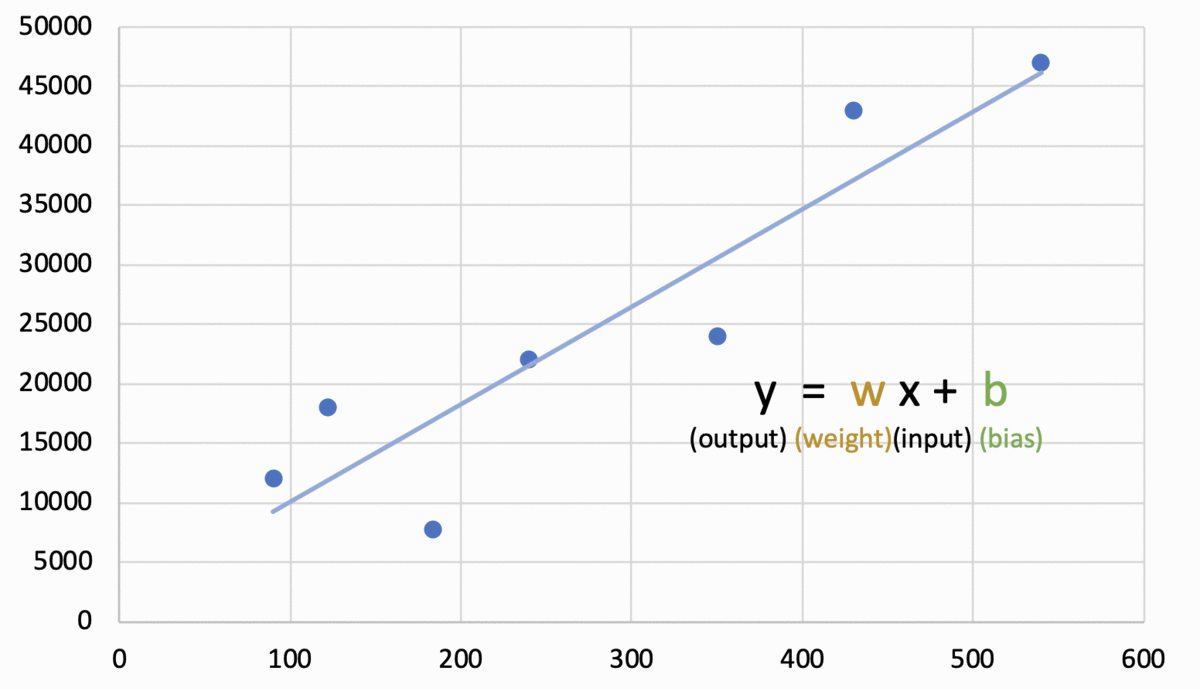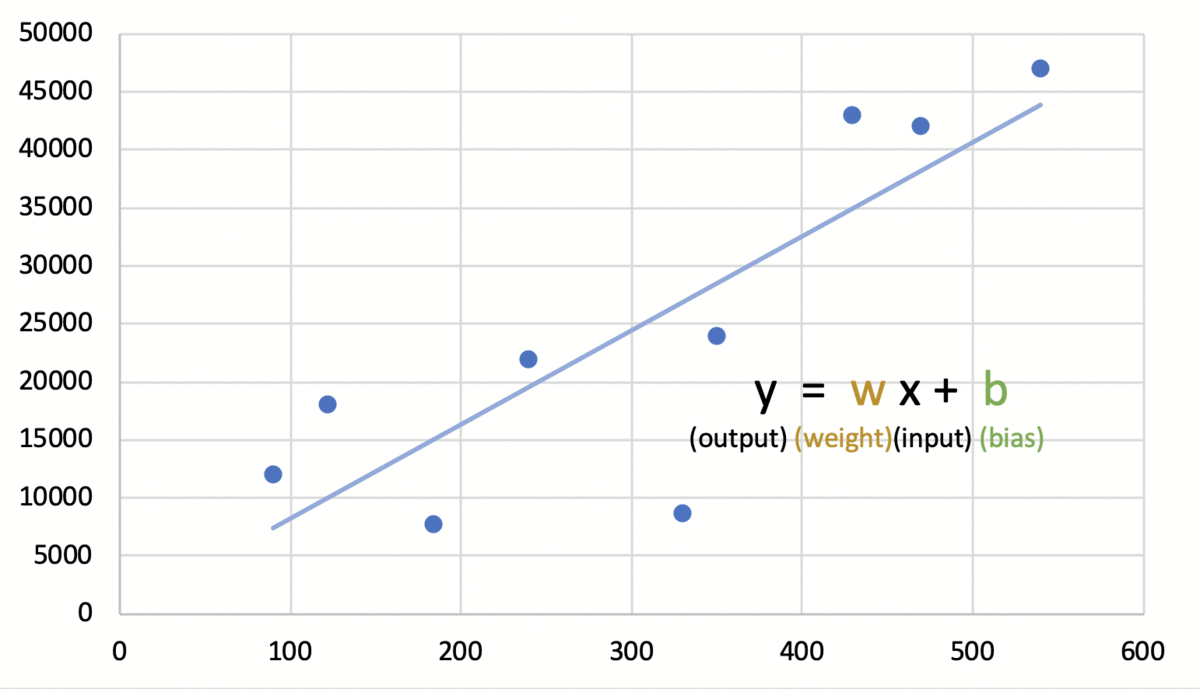
2. 기계학습의 구현 방법
| a. 데이터 수집 | b. 학습 모델 설정 | c. 훈련 데이터 입력 및 학습 | d. 시험 데이터 입력을 통한 성능 검증 | e. 활용 |
|
a. 데이터 수집: 데이터를 수집한다. 그리고 두 종류의 데이터로 나눈다. 1. 기계를 훈련시킬 때 이용할 훈련 데이터 2. 학습이 잘 되었는지 검증할 시험 데이터. 두 데이터로 나누는 이유는 훈련 데이터와 시험 데이터는 겹치지 않아야 하기 때문이다. 훈련 데이터에 썼던 데이터를 그대로 시험 데이터에 쓴다면 이 경우 당연히 좋은 결과가 나올 것이다. 하지만 이를 보고 기계가 성공적으로 학습하여 옳게 추론해 낸 결과물이라고 할 수 없기 때문이다. 이러한 이유로 기계를 잘 학습시키기 위해서는 훈련 데이터와 시험 데이터 모두 충분해야 하기에 양질의 많은 데이터가 필요하다.
예) 기계학습의 목표: 페이지 수에 따른 책 가격 책정. 소장하고 있는 책을 기반으로 페이지 수와 책의 가격 데이터를 정리한다. (페이지 수, 가격) (122, 18000), (240, 22000), (350, 24000), (540, 47000), (184, 7800) 훈련 데이터와 시험 데이터로 구분한다. 훈련 데이터: (122, 18000), (240, 22000), (350, 24000), (540, 47000) 시험데이터: (184, 7800)
|
|
b. 학습 모델 설정: 데이터 수집 후 학습 모델을 설정한다. (학습 모델의 종류와 각 특징에 대해서는 이후 다른 글에서 정리할 예정이다. 이번 글에서는 간단한 예시를 통해 학습 과정을 이해하는 것만을 목표로 한다.) 예) 가장 단순한 그래프 형태인 선형 그래프(일차 함수)로 학습 모델을 선정하였다.
|
|
c. 훈련 데이터 입력 및 학습: 설정한 학습 모델에 맞는 학습 알고리즘을 실행한다. 이 과정에서 훈련 데이터를 입력한다. 훈련 데이터는 학습용으로 입력되는 데이터이기에 샘플데이터(sample data, sample)라고도 불린다. 예) 주어진 데이터의 양상에 가장 잘 부합하는 일차함수를 찾는 알고리즘을 실행한다. 최적의 그래프를 구하는 것은 곧 그래프의 기울기를 나타내는 w(weight, 웨이트, 가중치)값과 y절편인 b(bias, 바이아스)의 최적의 값을 구하는 것이다. 그 결과 다음과 같은 그래프를 얻었다. (해당 알고리즘은 선형 회귀분석이라고 부르며 자세한 내용은 차후 새 글에서 다룰 것이다.) 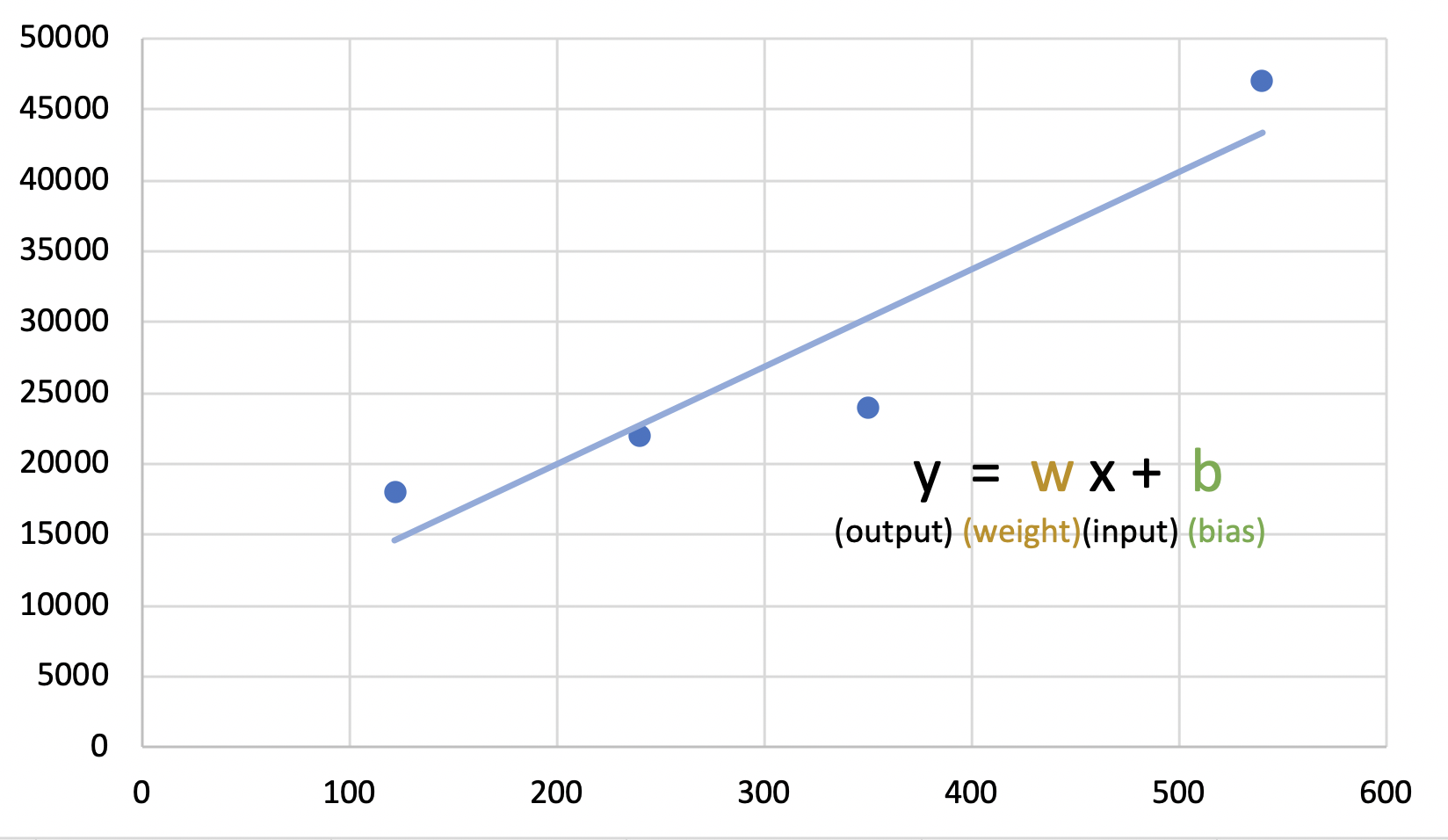 |
|
d. 시험 데이터 입력을 통한 성능 검증: 훈련을 시킨 후 시험 데이터를 입력하고 결과값을 분석해 성능을 검증한다. 점검한 성능에 맞게 알고리즘을 수정하는 등 피드백 과정을 거친다. 예)  시험 데이터 (184, 7800)의 페이지 수 184를 입력한 결과 초록색 점으로 나타난다. 이는 실제 데이터인 빨간색 점과는 큰 차이를 보임을 확인할 수 있다. 기존 훈련데이터에 시험데이터의 결과를 반영하여 5개의 데이터의 오차를 최소화하는 그래프로 다시 학습시킨다.  다시 학습시킨 결과는 위 그래프와 같다. 예시에서는 학습모델인 일차함수 형태와 이를 구하는 방법은 유지하되 일차함수의 기울기와 y절편 값을 조정하였다. 피드백에서 학습 모델 자체를 변경하거나 학습모델은 유지하되 이를 구하는 알고리즘을 수정할 수도 있다. |
|
e. 활용: 위의 과정들을 수 차례 반복하여 기계를 만족스러운 정도로 학습시켰다면 실제로 도구로서 이를 활용한다. 예) 학습이 어느 정도 이루어지면 이를 도구로 활용한다. 실제로는 위 과정들을 대량의 데이터를 통해 수없이 반복하겠지만 두 번째 그래프가 최적의 그래프임으로 결론지었다고 가정해보면 300페이지인 책의 가격을 책정하는 업무에 학습된 기계를 도구로 활용하면 25000원이라는 결과를 낼 것이다. |
이번 글을 통해서는 기계학습의 정의와 일반적인 기계학습의 과정에 대해 정리해 보았다. 기계학습은 위 과정을 일반적으로 따르되, 구체적인 방법에 따라 지도 학습, 비지도 학습, 강화 학습으로 나눌 수 있다. 다음 글을 통해서는 이들의 개념과 특징에 대해 정리해보고자 한다.
'AI > AI 기초 이론' 카테고리의 다른 글
| 6. 기계학습 방식의 종류 (0) | 2020.05.13 |
|---|---|
| 2. 인공지능의 세부 분야 (0) | 2020.04.16 |
| 1. 인공지능의 의미와 종류 (0) | 2020.04.06 |


